ABSTRACT
There is increased interest in using generative AI to create 3D spaces for virtual reality (VR) applications. However, today’s models produce artificial environments, falling short of supporting collaborative tasks that benefit from incorporating the user’s physical context. To generate environments that support VR telepresence, we introduce SpaceBlender, a novel pipeline that utilizes generative AI techniques to blend users' physical surroundings into unified virtual spaces. This pipeline transforms user-provided 2D images into context-rich 3D environments through an iterative process consisting of depth estimation, mesh alignment, and diffusion-based space completion guided by geometric priors and adaptive text prompts. In a preliminary within-subjects study, where 20 participants performed a collaborative VR affinity diagramming task in pairs, we compared SpaceBlender with a generic virtual environment and a state-of-the-art scene generation framework, evaluating its ability to create virtual spaces suitable for collaboration. Participants appreciated the enhanced familiarity and context provided by SpaceBlender but also noted complexities in the generative environments that could detract from task focus. Drawing on participant feedback, we propose directions for improving the pipeline and discuss the value and design of blended spaces for different scenarios.
Overview
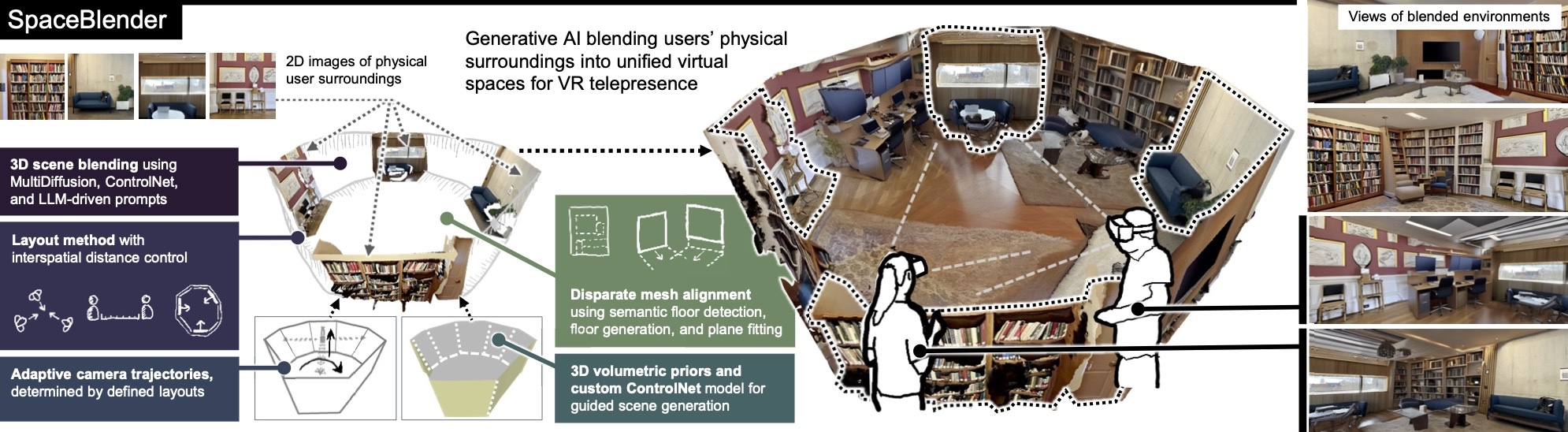
Overview of SpaceBlender, a pipeline that extends state-of-the-art generative AI models to blend users' physical surroundings into unified virtual environments for VR telepresence.
Video
5-minute narrated video overview of SpaceBlender, covering the motivation, pipeline, and evaluation of the system.
Pipeline Overview
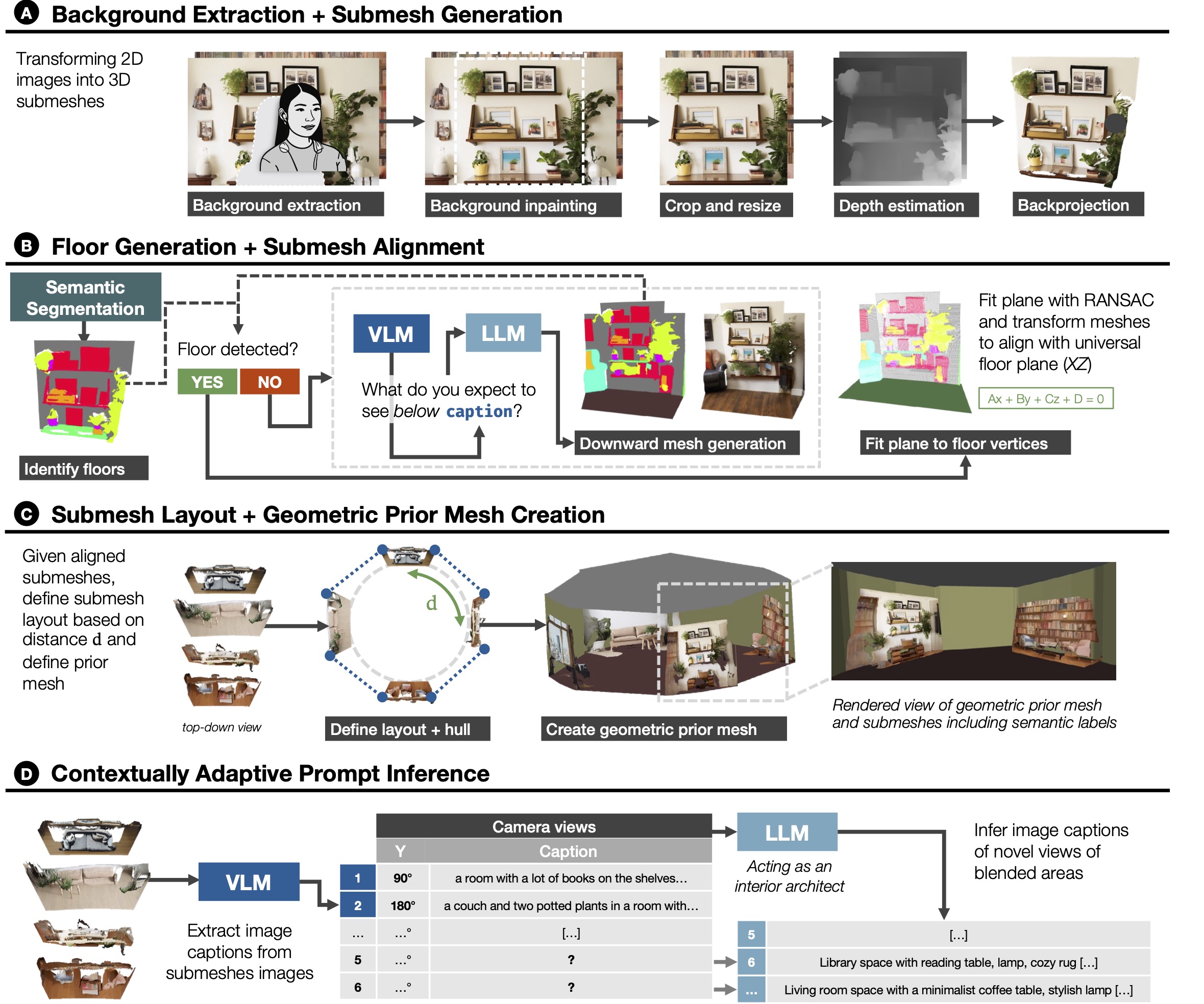
In Stage 1, each input image is first preprocessed, after which depth values of each pixel are estimated and backprojected to create a 3D mesh. We refer to the resulting n meshes as submeshes throughout this work. Next, the submeshes are aligned to a common floor plane with a RANSAC-based method applied to floor vertices identified by a semantic segmentation model, optionally including a floor generation step if no floor is visible in the image. The aligned submeshes are then positioned based on a parameter-based layout technique, based on which a geometric prior mesh is created to define the shape of the blended space. Lastly, text prompts describing the blended regions, i.e., the empty space between submeshes, of the environment are generated with a large language model (LLM) based on captions inferred by a visual language model (VLM).
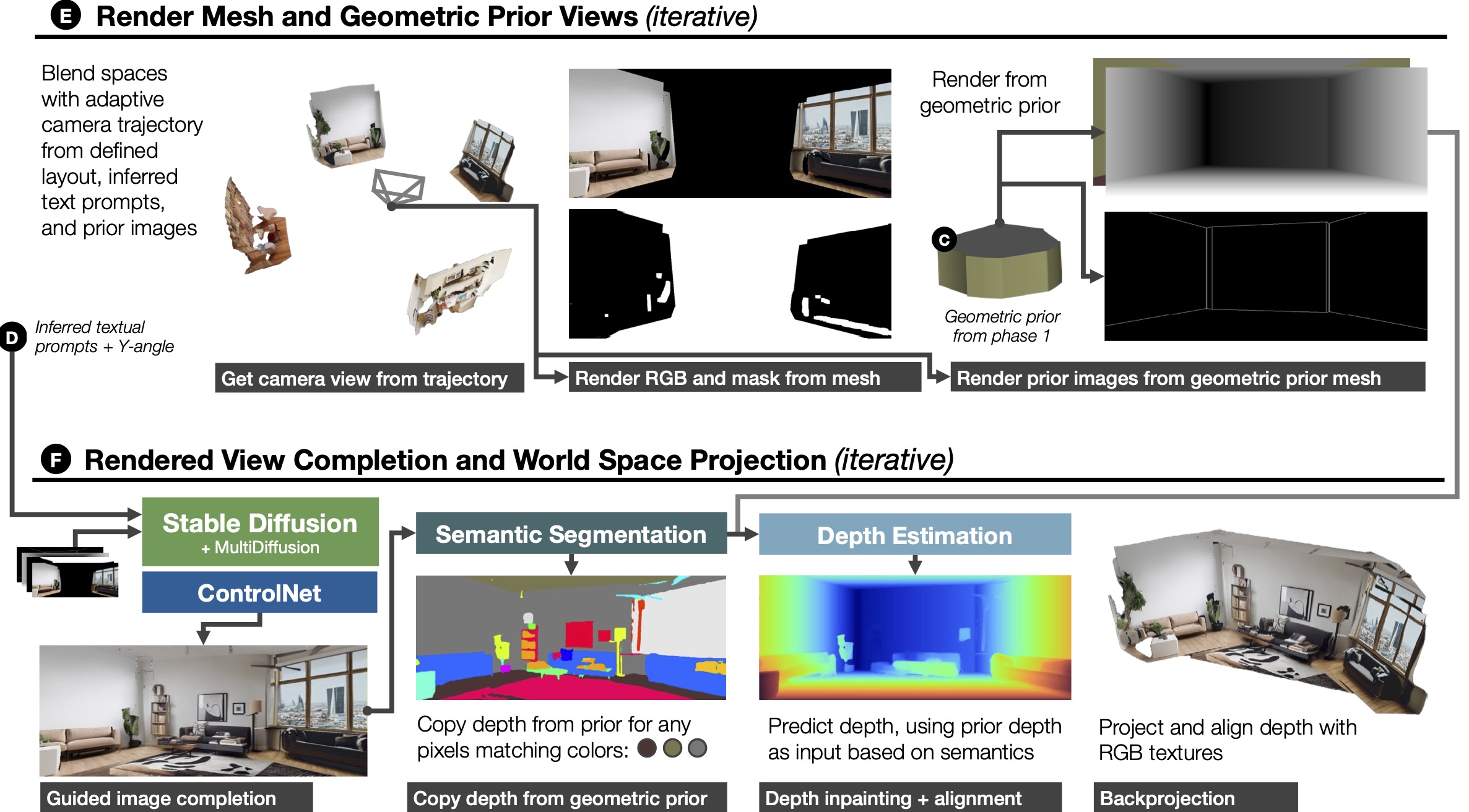
In Stage 2, the submeshes are blended through a process that involves repeatedly inpainting and integrating 2D rendered views of the mesh. For each iteration, based on the submesh layout defined in Stage 1, geometric image priors are rendered to function as a guide for the shape of the space. These are combined with the generated text prompts from Stage 1 to guide the content and appearance of the space. Once the blending process completes, an adaptive mesh completion trajectory is followed to fill remaining gaps in the environment.
Evaluation
Pairs of participants performing the affinity diagramming task in three different environments: Generic3D, Text2Room, and SpaceBlender.
CITING
@inproceedings{numanSpaceBlenderCreatingContextRich2024,
title = {{{SpaceBlender}}: {{Creating Context-Rich Collaborative Spaces Through Generative 3D Scene Blending}}},
shorttitle = {{{SpaceBlender}}},
booktitle = {Proceedings of the 37th {{Annual ACM Symposium}} on {{User Interface Software}} and {{Technology}}},
author = {Numan, Nels and Rajaram, Shwetha and Kumaravel, Balasaravanan Thoravi and Marquardt, Nicolai and Wilson, Andrew D},
year = {2024},
month = oct,
series = {{{UIST}} '24},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
doi = {10.1145/3654777.3676361},
}